Kubernetes 高可用集群和 DevOps 平台部署
Kubernetes 已然成为了云原生时代的操作系统,在容器管理、自动化编排等方面扮演着重要的角色。本文记录了部署 Kubernetes 高可用集群作为底层容器集群管理平台,并基于此部署 DevOps 平台的整体流程。
集群总览
集群一共有 7 个节点,各节点规划如下表:
| hostname | ip | |
|---|---|---|
| VIP | 10.219.12.8 | |
| LoadBalancer (haproxy + keepalived) | k8s-10-129-12-18 | 10.219.12.18 |
| k8s-10-129-12-19 | 10.219.12.19 | |
| Master (control plane) | k8s-10-129-12-13 | 10.219.12.13 |
| k8s-10-129-12-14 | 10.219.12.14 | |
| k8s-10-129-12-15 | 10.219.12.15 | |
| Minion/Worker/Node (data plane) | k8s-10-129-12-16 | 10.219.12.16 |
| k8s-10-129-12-17 | 10.219.12.17 |
集群基于 stacked etcd 拓扑,总体架构如下图:
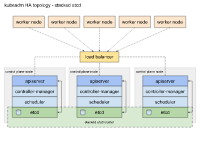
每个控制平面节点都运行 kube-apiserver,kube-scheduler 和kube-controller-manager 的实例。使用负载均衡器将 kube-apiserver 暴露给工作节点。
每个控制平面节点都创建一个本地 etcd 成员,并且该 etcd 成员仅与此节点的 kube-apiserver 通信。这同样适用于本地 kube-controller-manager 和 kube-scheduler实例。
这种拓扑将相同节点上的控制平面和 etcd 成员耦合在一起。与具有外部 etcd 节点的集群相比,建立起来更容易,并且复制管理起来也更容易。
集群规划使用 3 个控制节点是达到 HA 的基本条件,为了防止“脑裂”的出现。
准备
系统规划
所有节点系统使用 UEFI + GPT 安装,使用 lvm2 分区,留一个裸磁盘或划分一个裸分区给 ceph 作为集群的底层存储。
配置 ansible
Ansible 用于集群节点的批量操作非常方便,自身是基于 Python 开发的。
使用 k8s-10-129-12-18 节点作为 ansible 管理节点。配置 /etc/ansible/hosts 文件:
[k8s]
k8s-10-129-12-[13:17]:2892
[k8s-lb]
k8s-10-129-12-[18:19]:2892
[k8s-master]
k8s-10-129-12-[13:15]:2892
[k8s-worker]
k8s-10-129-12-[16:17]:2892
需要用到的 Ansible ad-hoc 命令:
- 复制文件到所有节点: ansible -m copy -a “src=test.txt dest=~/”
- 所有节点安装软件: ansible -m apt -b -K -a “name=chrony state=present”
- 工作节点执行 shell 命令: ansible k8s-worker -m shell -a “echo $PATH”
- sudo 权限执行: ansible k8s-worker -m shell -b -K -a “ll /var/lib/docker”
- 批量下载 docker 镜像
for i in `cat ~/gitlab.images`;do ansible k8s-worker -m shell -a "docker pull $i";done
同步时钟
执行 ansible -m apt -b -K -a "name=chrony state=present" 给所有节点安装 chrony 来同步时钟。底层时钟同步是分布式系统协同的保证。
同步 hostname 和 hosts
/etc/hostname
k8s-10-219-12-13 k8s-10-219-12-14 k8s-10-219-12-15 k8s-10-219-12-16 k8s-10-219-12-17 k8s-10-219-12-18 k8s-10-219-12-19
/etc/hosts
10.219.12.13 k8s-10-219-12-13.localhost k8s-10-219-12-13
同步基础软件和软件源
- docker && kubernetes
# step 1: 安装必要的一些系统工具
sudo apt update && sudo apt install apt-transport-https ca-certificates curl software-properties-common -y
# step 2: 安装GPG证书
curl -fsSL https://mirrors.aliyun.com/docker-ce/linux/ubuntu/gpg | sudo apt-key add -
curl https://mirrors.aliyun.com/kubernetes/apt/doc/apt-key.gpg | sudo apt-key add -
# Step 3: 写入软件源信息
sudo add-apt-repository "deb [arch=amd64] https://mirrors.aliyun.com/docker-ce/linux/ubuntu $(lsb_release -cs) stable"
sudo sh -c "echo 'deb https://mirrors.aliyun.com/kubernetes/apt/ kubernetes-xenial main' > /etc/apt/sources.list.d/kubernetes.list"
# Step 4: 更新并安装
sudo apt-mark unhold kubeadm kubectl kubelet
sudo apt update && sudo apt install docker-ce kubelet kubeadm kubectl -y
sudo apt-mark hold kubeadm kubectl kubelet
# Step 5: 清理
sudo apt autoremove -y && sudo apt autoclean -y
更新 kubeadm, kubectl, kubelet
sudo apt-mark unhold kubeadm kubectl kubelet
sudo apt update && sudo apt upgrade -y
sudo apt-mark hold kubeadm kubectl kubelet
同步 docker 配置
为了提高 docker 的最大性能,编辑 /etc/docker/daemon.json 文件
{
"exec-opts": ["native.cgroupdriver=systemd"],
"storage-driver": "overlay2",
"max-concurrent-downloads": 10,
"max-concurrent-uploads": 10,
"log-driver": "json-file",
"log-opts": {
"max-size": "10m",
"max-file": "1"
}
}
注意: 当 max-file 小于 2 或未设置 max-size 时compress 不能为 true.
负载均衡节点配置
使用 haproxy 和 keepalived 的组合实现负载均衡,作为 kube-apiserver 的代理,为整个集群提供流量入口。
直接使用集成了二者的 docker 镜像运行容器,启动负载均衡:
HAPROXY_CONFIG_FILE=/root/haproxy/haproxy.cfg
KEEPALIVED_CONFIG_FILE=/root/keepalived/keepalived.conf
docker run -it -d --net=host --privileged \
-v ${HAPROXY_CONFIG_FILE}:/usr/local/etc/haproxy/haproxy.cfg \
-v ${KEEPALIVED_CONFIG_FILE}:/etc/keepalived/keepalived.conf \
--name kubernetes-proxy \
haproxy-keepalived
harproxy.cfg 文件
global
daemon
maxconn 4000
log 127.0.0.1 local2
pidfile /var/run/haproxy.pid
defaults
mode http
log global
retries 3
timeout connect 10s
timeout client 1m
timeout server 1m
listen kubernetes-master
bind *:6443
mode tcp
balance roundrobin
server master1 10.219.12.13:6443 check maxconn 2000
server master2 10.219.12.14:6443 check maxconn 2000
server master3 10.219.12.15:6443 check maxconn 2000
listen kubernetes-http
bind *:80
mode tcp
balance roundrobin
server master1 10.219.12.13:80 check maxconn 2000
server master2 10.219.12.14:80 check maxconn 2000
server master3 10.219.12.15:80 check maxconn 2000
listen kubernetes-https
bind *:443
mode tcp
balance roundrobin
server master1 10.219.12.13:443 check maxconn 2000
server master2 10.219.12.14:443 check maxconn 2000
server master3 10.219.12.15:443 check maxconn 2000
listen kubernetes-ssh
bind *:22
mode tcp
balance roundrobin
server master1 10.219.12.13:22 check maxconn 2000
server master2 10.219.12.14:22 check maxconn 2000
server master3 10.219.12.15:22 check maxconn 2000
keepalived.conf 文件
global_defs {
router_id LVS_DEVEL
}
vrrp_script check_haproxy {
script "pgrep haproxy"
interval 2
weight -2
fall 10
rise 2
}
vrrp_instance VI_1 {
state MASTER
interface ens160
virtual_router_id 51
priority 300
advert_int 1
authentication {
auth_type PASS
auth_pass 35f18af7190d51c9f7f78f37300a0cbd
}
virtual_ipaddress {
10.219.12.8
}
track_script {
check_haproxy
}
}
控制节点配置
创建 kubeadm-config.yaml 文件
apiVersion: kubeadm.k8s.io/v1beta2
kind: ClusterConfiguration
kubernetesVersion: "v1.17.4"
controlPlaneEndpoint: "kubernetes.internal:6443"
imageRepository: "registry.aliyuncs.com/google_containers"
networking:
podSubnet: 192.168.0.0/16
apiServer:
extraArgs:
service-node-port-range: 22-32767
- 无法访问
k8s.gcr.io,设置imageRepository属性 - 无法访问
https://dl.k8s.io/release/stable-1.txt,设置kubernetesVersion属性的具体版本,不要用stable
第一个控制节点初始化
选择 k8s-10-219-12-13 作为第一个控制节点,执行
sudo kubeadm init --config=kubeadm-config.yaml --upload-certs
输出
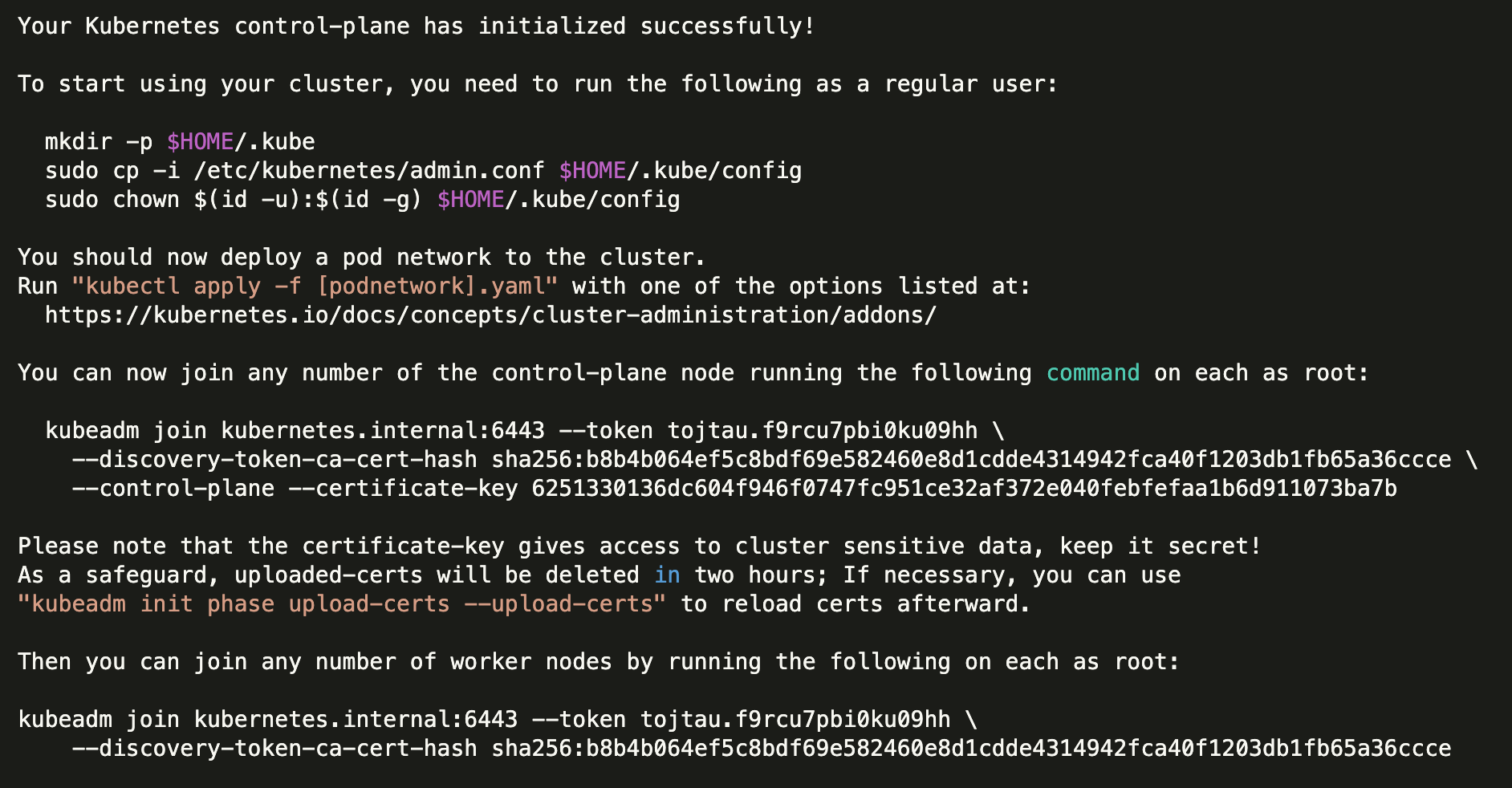
可以看到最后输出了一些帮助信息,分别是用于配置 kubectl 上下文的命令、用于添加工作节点的命令和用于添加其它控制节点的命令,记录下来稍后会用到。
部署CNI
Kubernetes 的网络模型是一个大扁平的网络模型,需要部署 CNI 插件为集群提供网络服务。这里选择 calico:
kubectl apply -f calico.yaml
其余控制节点加入
执行在初始化之后输出的添加命令,添加其它节点,执行后输出
...
To start administering your cluster from this node, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
Run 'kubectl get nodes' to see this node join the cluster.
看到最后也给出了需要执行的命令,用于配置 kubectl 上下文。
如果 certificate-key 过期了,则在控制节点执行 kubeadm init phase upload-certs --upload-certs 即可。
工作节点配置
所有控制节点加入到控制平面之后,就可以继续加入 worker 节点,在所有工作节点执行在初始化节点输出的加入工作节点命令,输出如下,注意没有使用到 certificate-key:
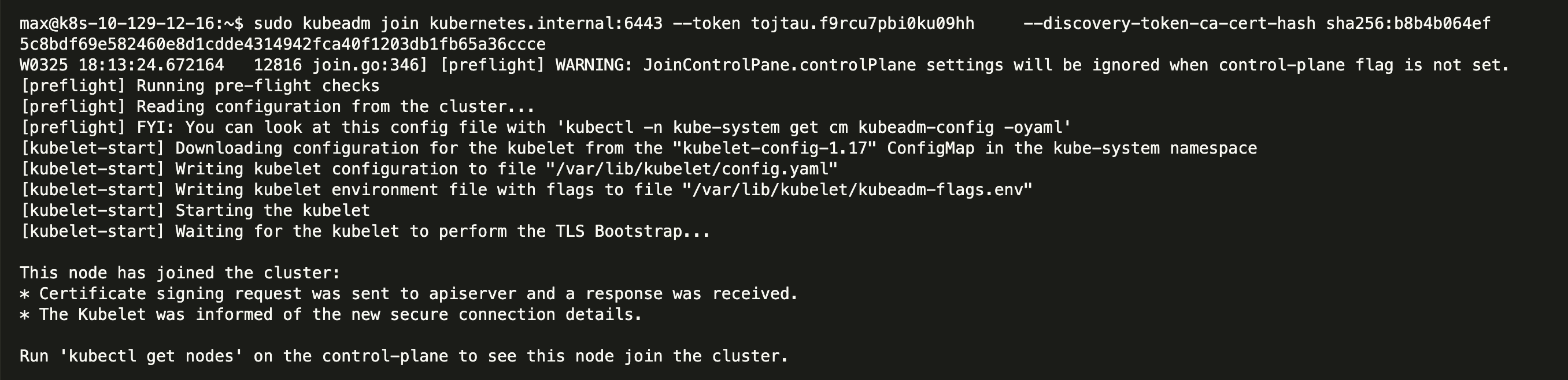
执行 kubectl get nodes 可以看到现在集群已经配置完成,接下来开始部署应用。
部署 Helm
Helm 被称为 Kubernetes 的包管理器,用于方便的部署其它云原生应用。
在节点 13 执行
wget https://get.helm.sh/helm-v3.1.2-linux-amd64.tar.gz && sudo tar xzf helm-v3.1.2-linux-amd64.tar.gz -C /usr/local/bin/ --strip-components=1 linux-amd64/helm
添加阿里云镜像
helm repo add stable http://mirror.azure.cn/kubernetes/charts
helm repo add apphub https://apphub.aliyuncs.com/
部署 MetalLB
由于 Kubernetes 本身的网络方案中的 LB 功能仅限于提供商,所以需要第三方插件来实现 LB 网络的功能, MetalLB 就是这样一个插件。
部署到 kube-network 命名空间中
kubectl create namespace kube-network
下载 Chart 包
helm pull stable/metallb
编辑 values.yaml 文件
configInline:
# Example ARP Configuration
address-pools:
- name: default
protocol: layer2
addresses:
- 10.219.12.200-10.219.12.250
安装
helm install metallb --namespace kube-network ./metallb
部署 nginx-ingress
nginx-ingress 用于提供 Ingress 服务。
部署到 kube-network 命名空间中
kubectl create namespace kube-network
安装
helm install nginx-ingress \
--namespace kube-network \
--set controller.image.repository="quay.azk8s.cn/kubernetes-ingress-controller/nginx-ingress-controller" \
--set controller.service.nodePorts.http=80 \
--set controller.service.nodePorts.https=443 \
--set controller.service.nodePorts.tcp.22=22 \
--set defaultBackend.image.repository="gcr.azk8s.cn/google-containers/defaultbackend-amd64" \
--set tcp.22="kube-gitlab/gitlab-gitlab-shell:22" \
stable/nginx-ingress
设置默认 SSL 证书
kubectl -n kube-network create secret tls default-ssl-certificate --cert=internal-server.crt --key=internal-server.key
然后更新 nginx-ingress-controller Deployment 的 spec.containers.args 增加一个参数
- '--default-ssl-certificate=kube-network/default-ssl-certificate'
然后集群里的所有的 Ingress 都有证书了,甚至不用更改 Ingress 的任何配置。 新的 Ingress 不用指定 tls.secretName 即可
注意 internal-server.crt 必须为证书链. 可以通过 Firefox 浏览器查看证书功能下载。
否则,Harbor registry 是无法登录的。因为 ingress 只返回了 server 证书,没有 intermediate 和 root 证书,所以无法信任。
部署 metrics-server
部署 HPA (如部署 GitLab) 必须要有 metrics-server
kubectl create namespace kube-metrics
部署
helm upgrade --install metrics-server \
--namespace kube-metrics \
--set rbac.pspEnabled=true \
--set hostNetwork.enabled=false \
--set args[0]="--v=2" \
--set args[1]="--kubelet-insecure-tls" \
--set args[2]="--kubelet-preferred-address-types=InternalIP" \
--set image.repository="gcr.azk8s.cn/google_containers/metrics-server-amd64" \
stable/metrics-server
部署好之后,Dashboard 会新增 CPU 和 Memory 的指标图
部署 Kubernetes Dashboard
Dashboard 是 K8s 官方提供的 GUI 工具,用于可视化查看集群的总体状态,还可以进行部署和扩缩容等操作。
部署到 kube-public 命名空间中
升级到使用 2.0
helm upgrade --install kubernetes-dashboard \
--namespace kube-public \
--set extraArgs[0]="--token-ttl=0" \
--set ingress.enabled=true \
--set ingress.hosts[0]="k8s.internal" \
--set ingress.tls[0].hosts[0]="k8s.internal" \
--set metricsScraper.enabled=true \
kubernetes-dashboard/kubernetes-dashboard
由于设置了全局 ingress 证书,所以安装 dashboard 时无需指定证书的 secret.
2.0 版本默认去掉了 admin 权限,需要手动添加下设置 cluster-admin 权限 s
cat << EOF | kubectl create -f -
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: kubernetes-dashboard
namespace: kube-public
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: cluster-admin
subjects:
- kind: ServiceAccount
name: kubernetes-dashboard
namespace: kube-public
EOF
部署 Rook
Rook 是一个存储编排工具,可以方便的部署 ceph 集群。
kubectl create namespace kube-storage
将部署到 15, 16, 17 三个节点,注意必须启用 rbd 内核模块
sudo modprobe rbd
部署 rook-ceph Operator
使用 rook 部署 ceph 集群是基于 Operator 实现的。
helm repo add rook-release https://charts.rook.io/release
helm upgrade --install rook-ceph \
--namespace kube-storage \
--set image.repository="dockerhub.azk8s.cn/rook/ceph" \
--set csi.cephcsi.image="quay.azk8s.cn/cephcsi/cephcsi:v2.0.0" \
--set csi.registrar.image="quay.azk8s.cn/k8scsi/csi-node-driver-registrar:v1.2.0" \
--set csi.provisioner.image="quay.azk8s.cn/k8scsi/csi-provisioner:v1.4.0" \
--set csi.snapshotter.image="quay.azk8s.cn/k8scsi/csi-snapshotter:v1.2.2" \
--set csi.attacher.image="quay.azk8s.cn/k8scsi/csi-attacher:v2.1.0" \
--set csi.resizer.image="quay.azk8s.cn/k8scsi/csi-resizer:v0.4.0" \
rook-release/rook-ceph
创建 Ceph 集群
OSD 的底层存储方式有两种 (storeType):
filestore。 用于目录.bluestore. 用于设备. 要单独挂一块硬盘 (如 /dev/sdc) 才能使用. 没有文件系统和分区的空硬盘设备。需要裸盘或裸分区
设置 master 节点可调度
max@k8s-10-219-12-13:~$ kubectl taint node k8s-10-129-12-15 node-role.kubernetes.io/master-
node/k8s-10-129-12-15 untainted
rook-cluster.yaml 文件
apiVersion: ceph.rook.io/v1
kind: CephCluster
metadata:
name: rook-ceph
namespace: kube-storage
spec:
...
storage: # cluster level storage configuration and selection
useAllNodes: true
useAllDevices: false
#deviceFilter:
config:
# The default and recommended storeType is dynamically set to bluestore for devices and filestore for directories.
# Set the storeType explicitly only if it is required not to use the default.
storeType: filestore
# Cluster level list of directories to use for filestore-based OSD storage. If uncomment, this example would create an OSD under the dataDirHostPath.
directories:
- path: /var/lib/storage
...
创建
kubectl create -f rook-cluster.yaml
然后就可以发现在 15, 16, 17 三个节点创建了 /var/lib/storage 目录,结构如下
/var/lib/storage/
├── kube-storage
│ ├── client.admin.keyring
│ ├── crash
│ ├── kube-storage.config
│ └── log
├── mon-a
│ └── data
├── mon-b
│ └── data
└── mon-c
└── data
创建 Pool 和 StorageClass
CephBlockPool
rook-block-storageclass.yaml 文件
apiVersion: ceph.rook.io/v1
kind: CephBlockPool
metadata:
name: replicapool
namespace: kube-storage
spec:
failureDomain: host
replicated:
size: 3
---
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: rook-ceph-block
annotations:
storageclass.kubernetes.io/is-default-class: "true"
# Change "rook-ceph" provisioner prefix to match the operator namespace if needed
provisioner: kube-storage.rbd.csi.ceph.com
parameters:
# clusterID is the namespace where the rook cluster is running
clusterID: kube-storage
# Ceph pool into which the RBD image shall be created
pool: replicapool
# RBD image format. Defaults to "2".
imageFormat: "2"
# RBD image features. Available for imageFormat: "2". CSI RBD currently supports only `layering` feature.
imageFeatures: layering
# The secrets contain Ceph admin credentials.
csi.storage.k8s.io/provisioner-secret-name: rook-csi-rbd-provisioner
csi.storage.k8s.io/provisioner-secret-namespace: kube-storage
csi.storage.k8s.io/node-stage-secret-name: rook-csi-rbd-node
csi.storage.k8s.io/node-stage-secret-namespace: kube-storage
# Specify the filesystem type of the volume. If not specified, csi-provisioner
# will set default as `ext4`.
#csi.storage.k8s.io/fstype: xfs
# Delete the rbd volume when a PVC is deleted
reclaimPolicy: Delete
创建
kubectl -n kube-storage create -f rook-block-storageclass.yaml
标记默认 StorageClass
kubectl annotate storageclasses.storage.k8s.io rook-ceph-block storageclass.kubernetes.io/is-default-class=true
CephFileSystem
rook-filesystem-storageclass.yaml 文件
apiVersion: ceph.rook.io/v1
kind: CephFilesystem
metadata:
name: cephfs
namespace: kube-storage
spec:
metadataPool:
replicated:
size: 3
dataPools:
- replicated:
size: 3
preservePoolsOnDelete: true
metadataServer:
activeCount: 1
activeStandby: true
---
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: rook-cephfs
# Change "rook-ceph" provisioner prefix to match the operator namespace if needed
provisioner: kube-storage.cephfs.csi.ceph.com
parameters:
# clusterID is the namespace where operator is deployed.
clusterID: kube-storage
# CephFS filesystem name into which the volume shall be created
fsName: cephfs
# Ceph pool into which the volume shall be created
# Required for provisionVolume: "true"
pool: cephfs-data0
# Root path of an existing CephFS volume
# Required for provisionVolume: "false"
# rootPath: /absolute/path
# The secrets contain Ceph admin credentials. These are generated automatically by the operator
# in the same namespace as the cluster.
csi.storage.k8s.io/provisioner-secret-name: rook-csi-cephfs-provisioner
csi.storage.k8s.io/provisioner-secret-namespace: kube-storage
csi.storage.k8s.io/node-stage-secret-name: rook-csi-cephfs-node
csi.storage.k8s.io/node-stage-secret-namespace: kube-storage
reclaimPolicy: Delete
创建
kubectl -n kube-storage create -f rook-filesystem-storageclass.yaml
s
访问 Ceph Dashboard
max@k8s-10-219-12-13:~$ kubectl -n kube-storage get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
rook-ceph-mgr-dashboard ClusterIP 10.101.182.69 <none> 8443/TCP 16h
默认是暴露一个 ClusterIP 类型的 Service。可以配置 Ingress 从集群外访问
apiVersion: networking.k8s.io/v1beta1
kind: Ingress
metadata:
name: rook-ceph-mgr-dashboard
namespace: kube-storage
annotations:
kubernetes.io/ingress.class: "nginx"
kubernetes.io/tls-acme: "true"
nginx.ingress.kubernetes.io/backend-protocol: "HTTPS"
nginx.ingress.kubernetes.io/server-snippet: |
proxy_ssl_verify off;
spec:
tls:
- hosts:
- ceph.internal
secretName: ceph.internal
rules:
- host: ceph.internal
http:
paths:
- path: /
backend:
serviceName: rook-ceph-mgr-dashboard
servicePort: https-dashboard
配置 ceph.internal 指向 10.219.12.8 就可以访问了
- 默认用户名:
admin - 默认密码:
kubectl -n kube-storage get secret rook-ceph-dashboard-password -o jsonpath="{['data']['password']}" | base64 --decode && echo
删除
# 1. Delete the Block and File artifacts
kubectl delete -n kube-storage cephblockpool replicapool
kubectl delete storageclass rook-ceph-block
# 2. Delete the CephCluster CRD
kubectl -n kube-storage delete cephcluster rook-ceph
# 3. Delete the Operator and related Resources
helm -n kube-storage uninstall rook-ceph
# 4. Delete the daemonsets
kubectl -n kube-storage delete daemonsets.apps csi-cephfsplugin
kubectl -n kube-storage delete daemonsets.apps csi-rbdplugin
# 4. Delete the data on hosts
sudo rm -rf /var/lib/storage
# 如果一直 Terminating, 强制删除 Pod
kubectl -n kube-storage delete pod --all --force --grace-period=0
# 或直接强制删除 namespace
kubectl delete namespace kube-storage --force --grace-period=0
# 删除 cluster-wide 资源
kubectl delete psp 00-rook-ceph-operator
kubectl delete crd objectbucketclaims.objectbucket.io
kubectl delete crd objectbuckets.objectbucket.io
部署 Harbor
Harbor 提供了私有 registry 的功能,而且能够存储 Helm Chart 等云原生制品。这是由中国团队开发的,非常强大。
kubectl create namespace kube-harbor
这里使用自有公钥创建 Secret harbor-harbor-ingress,不含 ca.crt 属性,这样 Harbor 不用下载证书。
helm upgrade --install harbor \
--namespace kube-harbor \
--set expose.type=ingress \
--set expose.tls.enabled=true \
--set expose.tls.secretName='harbor-harbor-ingress' \
--set expose.ingress.hosts.core=mirrors.internal \
--set expose.ingress.hosts.notary=notary.mirrors.internal \
--set externalURL=https://mirrors.internal \
--set notary.enabled=false \
--set clair.enabled=false \
--set trivy.enabled=false \
--set chartmuseum.enabled=true \
--set persistence.enabled=true \
harbor/harbor
- 默认用户:
admin - 默认密码:
Harbor12345
Harbor 可选组件:
Notary: 用于镜像签名. 可以通过--set notary.enabled=false禁用Clair: 用于镜像漏洞扫描. 可以通过--set clair.enabled=false禁用
导出根证书
有两种方式导出 CA 证书
- 通过 GUI (Harbor portal 的系统管理 - 配置管理 - 系统设置 - 镜像库根证书下载) 下载
- 通过 kubectl 导出为
mirrors.internal.ca.crt
kubectl -n kube-harbor get secrets harbor-harbor-ingress -o jsonpath="{.data.ca\.crt}" | base64 --decode > mirrors.internal.ca.crt
分发证书
Docker 证书设置
所有节点执行
sudo mkdir -p /etc/docker/certs.d/mirrors.internal
sudo cp mirrors.internal.ca.crt /etc/docker/certs.d/mirrors.internal/ca.crt
Helm 证书设置
需要使用 helm 的客户端需要设置
sudo cp mirrors.internal.ca.crt /etc/ssl/certs/mirrors.internal.ca.crt
部署 GitLab
DevOps 平台功能由 GitLab 提供。
kubectl create namespace kube-gitlab
使用 helm 部署
helm upgrade --install gitlab \
--namespace kube-gitlab \
--timeout 600s \
--set global.edition=ce \
--set global.hosts.domain=code.internal \
--set global.hosts.gitlab.name=code.internal \
--set global.hosts.gitlab.https=true \
--set global.hosts.registry.name=registry.code.internal \
--set global.hosts.registry.https=true \
--set global.hosts.minio.name=minio.code.internal \
--set global.hosts.minio.https=true \
--set global.ingress.class=nginx \
--set global.ingress.configureCertmanager=false \
--set nginx-ingress.enabled=false \
--set certmanager.install=false \
--set prometheus.install=true \
--set prometheus.alertmanager.enabled=false \
--set prometheus.kubeStateMetrics.enabled=false \
--set prometheus.nodeExporter.enabled=false \
--set prometheus.pushgateway.enabled=false \
--set gitlab-runner.install=false \
--set upgradeCheck.enabled=false \
gitlab/gitlab
输出如下:
WARNING: Automatic TLS certificate generation with cert-manager is disabled and no TLS certificates were provided. Self-signed certificates were generated.
You may retrieve the CA root for these certificates from the `gitlab-wildcard-tls-ca` secret, via the following command. It can then be imported to a web browser or system store.
kubectl get secret gitlab-wildcard-tls-ca -ojsonpath='{.data.cfssl_ca}' | base64 --decode > code.internal.ca.pem
If you do not wish to use self-signed certificates, please set the following properties:
- global.ingress.tls.secretName
OR
- global.ingress.tls.enabled (set to `true`)
- gitlab.unicorn.ingress.tls.secretName
- registry.ingress.tls.secretName
- minio.ingress.tls.secretName
WARNING: If you are upgrading from a previous version of the GitLab Helm Chart, there is a major upgrade to the included PostgreSQL chart, which requires manual steps be performed. Please see our upgrade documentation for more information: https://docs.gitlab.com/charts/installation/upgrade.html
- 默认用户名:
root - 默认密码: 在 Secret
gitlab-gitlab-initial-root-password
导出根证书
- 使用 kubectl 导出为
code.internal.ca.crt
kubectl -n kube-gitlab get secrets gitlab-wildcard-tls-ca -ojsonpath="{.data.cfssl_ca}" | base64 --decode > code.internal.ca.crt
分发证书
Docker 证书设置
所有节点执行
sudo mkdir -p /etc/docker/certs.d/registry.code.internal
sudo cp code.internal.ca.crt /etc/docker/certs.d/registry.code.internal/ca.crt
CA 证书设置 需要执行 https pull 的节点执行:
sudo cp code.internal.ca.crt /etc/ssl/certs/
部署 GitLab Runner
GitLab Runner 是实际的 CI/CD 任务的执行者。
首先根据 gitlab 的根证书创建 Secret:
cp code.internal.ca.crt code.internal.crt
cp code.internal.ca.crt registry.code.internal.crt
cp mirrors.internal.ca.crt mirrors.internal.crt
kubectl -n kube-gitlab create secret generic gitlab-runner.crt --from-file code.internal.crt --from-file registry.code.internal.crt --from-file mirrors.internal.crt
部署一个 Shared Runner:
helm upgrade --install gitlab-runner-shared \
--namespace kube-gitlab \
--set gitlabUrl="https://code.internal" \
--set runnerRegistrationToken="WIRNHWqSIlCi1vh0W3IGiDPMtgs58YGdB01aVLSCuHrPkCmY8xrOtUaRu97LEOiq" \
--set certsSecretName="gitlab-runner.crt" \
--set rbac.create=true \
--set rbac.clusterWideAccess=true \
--set runners.privileged=true \
--set runners.imagePullPolicy="always" \
--set image="gitlab/gitlab-runner:alpine-v12.9.0" \
gitlab/gitlab-runner
设置 --set runners.imagePullPolicy="always" 表示每次 Runner 都去拉最新的 build 镜像.
总结
至此,Kubernetes 高可用集群已搭建完成,基于 GitLab 的 DevOps 平台也已部署就位,接下来就是去使用、去深入。
当然,目前的集群已然存在很多问题,比如 etcd 是堆叠的,数据没有做进一步保障等,也需要进一步解决。
参考
- Kubernetes HA, https://kubernetes.io/docs/setup/independent/high-availability
- Kubernetes Ingress, https://kubernetes.io/docs/concepts/services-networking/ingress
- Nginx Ingress, https://github.com/kubernetes/ingress-nginx
- Helm, https://helm.sh/
- MetalLB, https://metallb.universe.tf/
- Rook, https://rook.io
- Harbor, https://goharbor.io/
- GitLab Runner, https://gitlab.com/gitlab-org/gitlab-runner/