NVIDIA 宣布 containerd 支持 NVIDIA GPU Operator
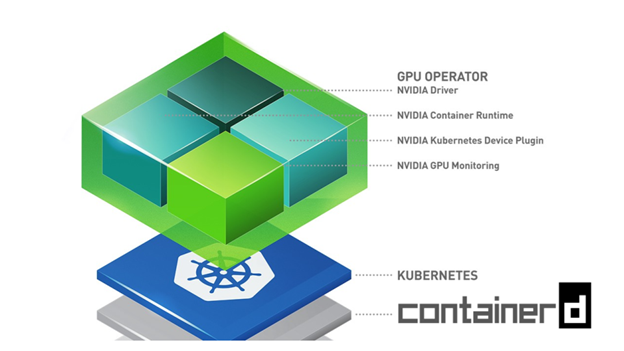
多年来,docker 是 Kubernetes 支持的唯一容器运行时。随着时间的推移,对其他运行时的支持不仅成为可能,而且通常是首选,因为围绕通用容器运行时接口 (CRI) 的标准化已在更广泛的容器生态系统中得到巩固。随着 docker 努力跟上对 CRI 的支持,诸如 containerd 和 cri-o 之类的运行时越来越受欢迎。
从 Kubernetes 1.20 开始,对 docker 的支持已被弃用,这促使许多人重新考虑他们未来对容器运行时的选择。对于现有的 docker 用户,明显且风险较小的选择是 containerd,因为 docker 底层已经是基于 containerd 运行。从用户的角度来看,这种转变将是完全透明的。
直到最近,NVIDIA GPU Operator 仅在使用 docker 或 cri-o 作为底层容器运行时的 Kubernetes 上运行。从版本 1.4.0 开始,也提供了对 containerd 的集成支持。
支持 containerd 一直是 GPU Operator 的一项长期功能要求,因为它使 microK8s 等系统(仅在 containerd 上运行)和 NVIDIA 边缘计算平台 (EGX) 能够覆盖更广泛的用户。
以最简单的形式,部署具有 containerd 支持的 GPU 算子只需在 Helm Chart 中设置一个值并运行 helm install:
helm install --wait --generate-name \
nvidia/gpu-operator \
--set operator.defaultRuntime="containerd"
在这篇博客中,您将了解如何在 GPU Operator 中启用容器化支持、可用的可自定义功能以及它的工作原理。
在 GPU Operator 中支持 containerd
NVIDIA GPU Operator 简化了 Kubernetes 中的 GPU 生命周期管理。使用单个 helm 命令,您可以将 GPU Operator 安装到 Kubernetes 集群上,并使 GPU 可供最终用户使用。
在底层,Node Feature Discovery 用于检测配备 GPU 的集群节点并为其提供任何所需的软件组件。其中包括 NVIDIA GPU 驱动程序、NVIDIA 容器运行时、Kubernetes 设备插件、DCGM 监控代理和 GPU 功能发现。安装后,GPU Operator 会持续监控集群的状态,将这些组件添加到任何新的 GPU 节点,这些节点会随着时间的推移而连接。 GPU Operator 的高级状态机如下所示。
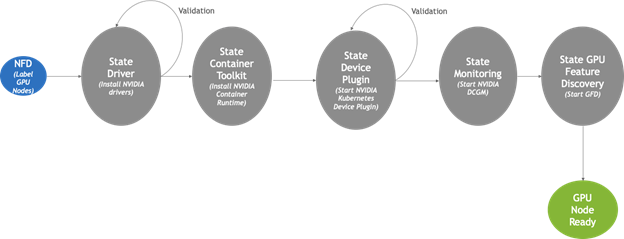
向 GPU Operator 添加 containerd 支持的大部分工作是在上图所示的 Container Toolkit 组件中完成的。通常,Container Toolkit 负责在主机上安装 NVIDIA 容器运行时。它还确保 Kubernetes 使用的容器运行时(例如 docker、cri-o 或 containerd)经过正确配置,以在底层使用 NVIDIA 容器运行时。
对于 containerd 支持,这涉及以下步骤:
- 在主机上安装 NVIDIA 容器运行时
- 更新
containerd配置文件以指向这个新安装的运行时 - 向
containerd发送 SIGHUP 以强制配置更改生效
其余的工作只是添加必要的管道以通过 helm 提供此功能。以下代码示例显示了可用于配置具有 containerd 支持的 GPU Operator 的 helm 设置。
operator:
defaultRuntime: containerd
toolkit:
env:
- name: CONTAINERD_CONFIG
value: /etc/containerd/config.toml
- name: CONTAINERD_SOCKET
value: /run/containerd/containerd.sock
- name: CONTAINERD_RUNTIME_CLASS
value: nvidia
- name: CONTAINERD_SET_AS_DEFAULT
value: true
唯一需要的设置是将 operator.defaultRuntime 设置为 containerd。这会触发 GPU Operator 加载具有 containerd 支持的 Container Toolkit。其余设置是可选的,用于自定义底层的特定容器设置。前面显示的值是默认值。
-
CONTAINERD_CONFIG:主机上到containerd配置的路径已更新,支持nvidia-container-runtime。默认情况下,它指向/etc/containerd/config.toml(containerd的默认位置)。如果您的containerd安装不在默认位置,则应自定义此值。 -
CONTAINERD_SOCKET:主机上用于与containerd通信的套接字文件的路径。Operator 使用它向containerd守护进程发送SIGHUP信号以重新加载其配置。默认情况下,它指向/run/containerd/containerd.sock(containerd 的默认位置)。如果您的containerd安装不在默认位置,则应自定义此值。 -
CONTAINERD_RUNTIME_CLASS:与nvidia-container-runtime关联的RuntimeClass资源的名称。使用等于CONTAINERD_RUNTIME_CLASS的runtimeClassName值启动的 Pod 始终与nvidia-container-runtime一起运行。默认的CONTAINERD_RUNTIME_CLASS值为nvidia。 -
CONTAINERD_SET_AS_DEFAULT:指示是否将nvidia-container-runtime设置为用于启动所有容器的默认运行时。当设置为false时,只有运行时类名值等于CONTAINERD_RUNTIME_CLASS的 Pod 中的容器会与nvidia-container-runtime一起运行。默认值是true。
以下代码示例使用 containerd 支持和前面描述的每个可选设置的显式值启动 GPU Operator。
helm install --wait --generate-name \
nvidia/gpu-operator \
--set operator.defaultRuntime=containerd \
--set toolkit.env[0].name=CONTAINERD_CONFIG \
--set toolkit.env[0].value=/etc/containerd/config.toml \
--set toolkit.env[1].name=CONTAINERD_SOCKET \
--set toolkit.env[1].value=/run/containerd/containerd.sock \
--set toolkit.env[2].name=CONTAINERD_RUNTIME_CLASS \
--set toolkit.env[2].value=nvidia \
--set toolkit.env[3].name=CONTAINERD_SET_AS_DEFAULT \
--set toolkit.env[3].value=true
以上。您现在应该拥有启动 GPU Operator 并使用 containerd 运行所需的所有工具。更多信息,请参考官方文档。